
This revelation, validated by empirical observations and formalized in recent academic surveys, challenges conventional wisdom that often prioritizes model selection and prompt engineering. Instead, the focus is shifting towards developing robust memory systems that enable agents to maintain context, learn from past interactions, and adapt their behavior effectively.
The Foundational Shift: Memory Over Model
The notion that memory architecture trumps model choice is a profound recalibration for the AI community. A recent survey paper, "Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers" (arxiv 2603.07670), starkly articulates this, stating: "The gap between ‘has memory’ and ‘does not have memory’ is often larger than the gap between different LLM backbones." This assertion underscores a fundamental truth discovered by many working with multi-agent systems. When disparate agentic systems, such as proprietary code-generation agents like Claude Code or agents deployed in cloud environments, attempt to collaborate, challenges related to coordination, memory retention, and state management escalate dramatically.
This observation is not merely theoretical; it aligns closely with the experiences of practitioners building and managing complex agent networks. For instance, in a distributed multi-agent system like OpenClaw, comprising research agents, writing agents, simulation engines, and heartbeat schedulers, asynchronous collaboration and context hand-offs rely heavily on shared files and persistent state. The moment external systems are introduced, the fragility of a poorly designed memory system becomes painfully evident. This is because LLMs, by their very nature, are largely stateless. Each interaction is treated as a new prompt, and without external mechanisms, they lack the capacity for sustained learning or long-term recall. Memory, in this context, functions as the agent’s belief state within a Partially Observable Markov Decision Process (POMDP) structure, enabling it to build and maintain an internal model of a partially observable world. An inaccurate or incomplete internal model inevitably leads to degraded decision-making and performance.
The Write-Manage-Read Loop: Beyond Simple Storage
The survey paper characterizes agent memory not as a simple "store and retrieve" function, but as a dynamic write-manage-read loop. This distinction is crucial. While most implementations adequately handle the "write" (storing information) and "read" (retrieving information) phases, the "manage" phase is frequently neglected. This oversight leads to an uncurated accumulation of data, resulting in noise, contradictions, and bloated context windows.
Effective memory management involves sophisticated processes such as summarizing, prioritizing, escalating information to long-term storage, and aging out irrelevant data. Without these mechanisms, agents can become overwhelmed, leading to degraded performance. Early efforts to address this might involve heuristic control policies, defining rules for data retention and summarization. However, for large, distributed systems, more robust solutions are necessary, often leveraging specialized memory systems like those found in AgentCore, vector databases, or custom file-based architectures. The challenge lies in moving beyond basic data persistence to intelligent curation and active management of an agent’s knowledge base.
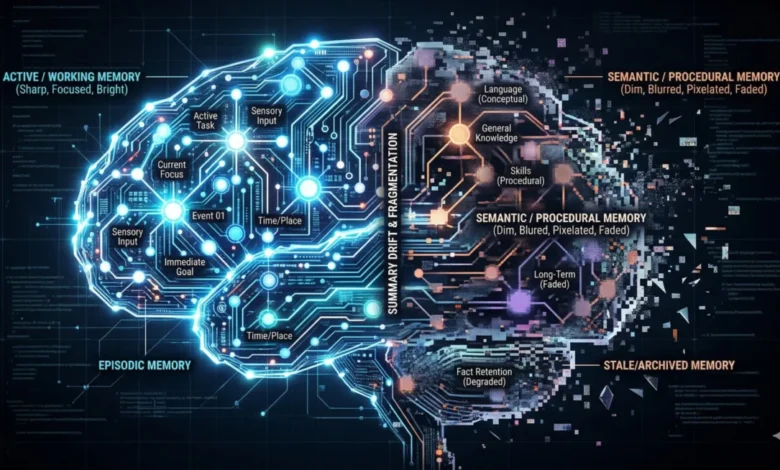
Temporal Scopes of Memory: A Structured Approach
To better understand and implement agent memory, the paper delineates four distinct temporal scopes, each serving a unique purpose and presenting its own set of challenges and solutions:
-
Working Memory: This is essentially the context window of an LLM. It is ephemeral, high-bandwidth, and severely limited in capacity. All immediate processing and interaction occur here. The primary failure mode is "attentional dilution" or the "lost in the middle" effect, where relevant information is overlooked due to an overcrowded context window. This is a common issue observed in tools like Claude Code or chatbots where extended conversations degrade performance, necessitating the creation of new threads to reset the context. Despite advancements in context window sizes, the problem of efficient information utilization within these large windows persists.
-
Episodic Memory: This scope captures concrete experiences, recording "what happened, when, and in what sequence." It forms a searchable timeline of events, allowing agents to review past actions, identify patterns, and avoid repeating mistakes. Practical applications include daily standup logs where agents summarize their activities and findings. Tools like Agent Core’s short-term memory features are designed to retain these interaction histories, often with mechanisms to determine which episodes warrant longer-term persistence. This distinct tier is vital for agents to learn from their operational history.
-
Semantic Memory: This tier is responsible for abstracted, distilled knowledge, facts, heuristics, and learned conclusions. Unlike episodic memory, which records raw events, semantic memory is curated, storing only information deemed valuable as a lasting truth. This might manifest as a "MEMORY.md" file in an agent’s workspace or be managed by a dedicated long-term memory feature in platforms like Agent Core. The curation step is paramount; without it, semantic memory can devolve into an unstructured "junk drawer," undermining its utility.
-
Procedural Memory: This encompasses encoded executable skills, behavioral patterns, and learned actions. It defines an agent’s persona, operational constraints, and escalation rules. In systems like OpenClaw, this could be stored in configuration files (e.g., AGENTS.md, SOUL.md) that dictate the agent’s behavior at the start of a session. Crucially, procedural memory should not be static; it ought to be updated based on user feedback or through "dream" processes that analyze past interactions to refine behaviors. Neglecting the feedback mechanisms for updating procedural memory is a common oversight, leading to static agent personas that fail to adapt and improve over time, despite extensive initial prompt tuning.
Mechanisms for Memory Management: An Evolving Landscape
The implementation of these memory scopes relies on various mechanisms, each with its strengths and weaknesses:
-
Context-Resident Compression: This involves techniques like sliding windows, rolling summaries, and hierarchical compression, aiming to keep information within the immediate context window. While seemingly efficient, repeated compression can lead to "summarization drift," where details are lost, and the memory no longer accurately reflects past events. This is evident in tools that aggressively summarize conversations, often necessitating a fresh start to regain clarity.
-
Retrieval-Augmented Stores (RAG): This widely adopted approach applies RAG principles to an agent’s interaction history. Agents embed past observations and retrieve relevant memories based on similarity. While powerful for long-running agents with extensive histories, retrieval quality is a critical bottleneck. Issues like "semantic vs. causal mismatch" arise when similarity searches return related but causally irrelevant memories, leading to inefficient debugging or "thrashing" behavior. Furthermore, the inability to query for specific temporal events (e.g., "what happened last Monday") highlights a limitation of purely semantic retrieval.
-
Reflective Self-Improvement: Systems like Reflexion and ExpeL allow agents to write post-mortems and store conclusions, enabling learning from mistakes. This concept extends to "dream"-based reflection and patterns like Google’s Memory Agent. The promise is agents that iteratively improve, but the risk of "self-reinforcing errors" (confirmation loops) where an agent internalizes incorrect information as ground truth is significant.
-
Hierarchical Virtual Context: Inspired by operating system architectures, this approach, exemplified by MemGPT, conceptualizes a main context window as "RAM," a recall database as "disk," and archival storage as "cold storage," with the agent managing its own paging. While theoretically elegant, the overhead and complexity of maintaining these distinct tiers have hindered widespread production adoption, with little evidence of real-world deployment despite its conceptual appeal.
-
Policy-Learned Management: This represents an emerging frontier where reinforcement learning (RL) is used to train operators (store, retrieve, update, summarize, discard) that models learn to invoke optimally. This promises highly adaptive and efficient memory management but is still in its nascent stages, lacking mature tooling for builders and demonstrable production use cases.
Navigating Failure Modes: The Perils of Imperfect Memory
The sophistication of memory systems brings with it complex failure modes that can subtly, yet profoundly, degrade agent performance:
- Context-Resident Failures: Beyond summarization drift, "attention dilution" plagues agents even with massive context windows. Information buried in the middle of a lengthy prompt can be ignored, leading to agents "having" the information but not "using" it effectively.
- Retrieval Failures: The "semantic vs. causal mismatch" inherent in RAG systems means agents might retrieve superficially similar memories that don’t address the root cause of an issue. "Memory blindness" occurs when crucial facts exist but are never resurfaced due, for example, to an inadequate retrieval limit. Most dangerously, "silent orchestration failures" in paging or archival policies can degrade responses without throwing explicit errors, manifesting only as generic or ungrounded agent behavior.
- Knowledge-Integrity Failures: "Staleness" is ubiquitous; agent memory can quickly become outdated as the real world evolves, leading to decisions based on obsolete information. "Self-reinforcing errors" or confirmation loops occur when a flawed memory is treated as ground truth, distorting the agent’s worldview. "Over-generalization" is a quieter form, where a specific workaround becomes a default pattern applied inappropriately across diverse contexts.
- Environmental Failure: "Contradiction handling" poses a significant challenge. When new information conflicts with existing knowledge, agents struggle to determine the actual truth, leading to oscillatory behavior where they waver between conflicting beliefs.
Design Tensions and Governance Challenges
Building effective memory systems is a balancing act across several inherent design tensions:
- Utility vs. Efficiency: More comprehensive memory often demands greater computational resources, higher latency, and increased storage.
- Utility vs. Adaptivity: Memory that is highly useful today may become stale tomorrow. The process of updating and adapting memory is both expensive and carries inherent risks.
- Adaptivity vs. Faithfulness: The more memory is updated, revised, or compressed, the greater the risk of distorting or losing the original, faithful representation of events.
- Faithfulness vs. Governance: Accurate memory may contain sensitive information (PHI, PII) that requires deletion, obfuscation, or protection due to privacy regulations (e.g., GDPR, HIPAA). This introduces complex compliance requirements that often conflict with the desire for comprehensive and persistent memory.
Practical Takeaways for AI Builders
For engineering teams embarking on the journey of building autonomous agents, several practical takeaways emerge:
- Start with Explicit Temporal Scopes: Avoid the trap of building a monolithic "memory" system. Instead, address memory needs incrementally, building episodic memory when required, then semantic memory as use cases evolve. Do not prematurely optimize for every form of memory.
- Take Management Seriously: Proactively plan for memory maintenance. This includes strategies for compression, connection, and "dream" behaviors, as well as clear rules for what information transitions to semantic memory versus RAG. Without robust management, systems will inevitably accumulate noise and contradictions.
- Retain Raw Episodic Records: Summaries are prone to drift and detail loss. Maintaining raw records provides an auditable trail and allows agents to revisit original events when necessary, ensuring faithfulness.
- Version Reflective Memory: Implement timestamps or versioning for summaries, long-term memories, and compressions. This provides a crucial mechanism for agents to determine the most current and accurate reflection of the system’s state, mitigating contradictions.
- Treat Procedural Memory as Code: Configuration files, persona instructions, and behavioral constraints—all forms of procedural memory—should be treated with the same rigor as application code. Placing them under source control enables tracking changes, facilitates review, and is particularly vital for autonomous systems that can self-alter these parameters based on feedback.
Conclusion and Future Outlook
The "write-manage-read" framework provides an invaluable lens through which to conceptualize and build agent memory systems. It forces builders to consider all three phases, moving beyond the simplistic "store and retrieve" paradigm. The striking alignment between this formal taxonomy and the hard-won insights of practitioners underscores the paper’s significance. It formalizes patterns independently discovered through iteration and frustration, offering a shared vocabulary and framework for the nascent field of autonomous agent development.
While significant strides have been made, the landscape of agent memory is still ripe with open problems. Evaluation methodologies remain primitive, governance considerations are often an afterthought in practice, and promising new approaches like policy-learned management are still in their infancy. This vast "runway" signifies immense potential for innovation and differentiation. Ultimately, the true power and capability of future AI agent systems will not be defined by the size or sophistication of their underlying models, but by the intelligence and robustness of their memory architectures. This critical component is where the real work—and the real breakthroughs—will occur.







{kind=link}